[Kafka] 아파치 카프카(Apache Kafka) 구성 요소 및 동작 방식
Apache Kafka Components 소개
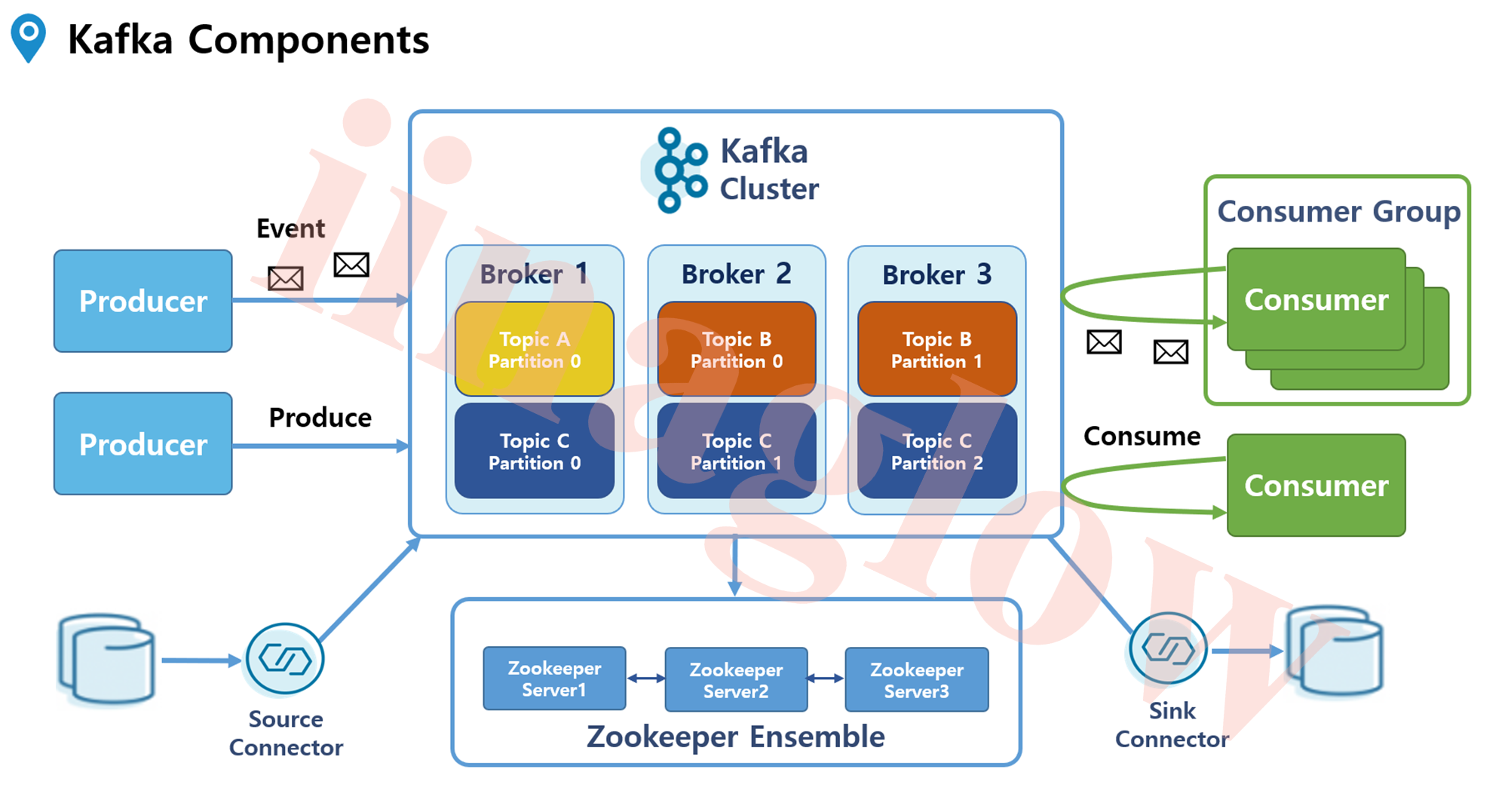
Kafka는 대규모 실시간 데이터 스트리밍 플랫폼으로, 데이터를 생성하고 처리하는 다양한 컴포넌트로 구성됩니다. 이 글에서는 카프카의 주요 구성 요소인 프로듀서, 컨슈머, 토픽, 파티션, 브로커, 주키퍼, 그리고 커넥터에 대해 알아보겠습니다.
1. 프로듀서 & 컨슈머 (Producer & Consumer)
Kafka에서 데이터를 생성하고 보내는 역할은 프로듀서가, 데이터를 가져와 처리하는 역할은 컨슈머가 담당합니다.
Producer: 메시지를 만들어 특정 토픽으로 데이터를 보냅니다.Consumer: 토픽에서 데이터를 폴링(polling) 방식으로 가져와 처리합니다.
이때 화살표의 방향을 잘 보면 데이터의 흐름을 나타냅니다. 컨슈머는 데이터를 U턴하여 가져오는 방식으로 동작합니다. 이는 실제로 카프카에서 데이터를 보내는 방식이 아니라, 컨슈머에서 데이터를 가져오는 방식을 나타냅니다.
2. 토픽 & 파티션 (Topic & Partition)
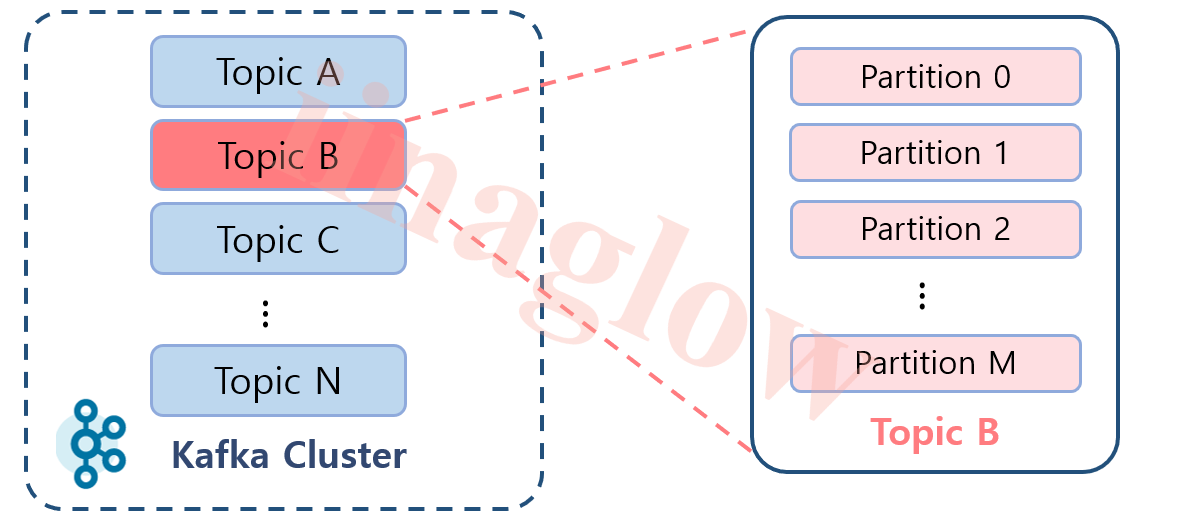
토픽은 Kafka에서 데이터가 저장되는 논리적인 개념입니다. 실제 데이터는 토픽 내의 파티션에 저장됩니다.
Topic: 논리적인 개념으로, 디렉토리나 파일처럼 눈에 보이지 않습니다.Partition: 실제 데이터를 저장하는 단위로, 하나의 토픽은 여러 파티션으로 나뉠 수 있습니다.
예를 들어, Topic B와 C처럼 파티션이 여러 개인 경우, 데이터가 분산되어 여러 브로커에서 병렬로 처리될 수 있습니다. 이를 통해 데이터 처리 성능을 향상시킬 수 있습니다.
3. 브로커 & 주키퍼 (Broker & Zookeeper)
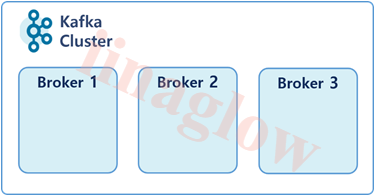
브로커는 Kafka의 핵심 컴포넌트로, 프로듀서와 컨슈머 사이에서 데이터 스트림을 안정적으로 관리하는 역할을 합니다.
Broker
- 클라이언트와 데이터를 주고받기 위한 주체입니다.
- Topic 내의 Partition 들을 분산 및 유지 관리합니다.
- 각각의 Broker는 모든 Broker, Topic, Partition에 대해 인지하고 있으며 데이터를 안정적으로 전달합니다.
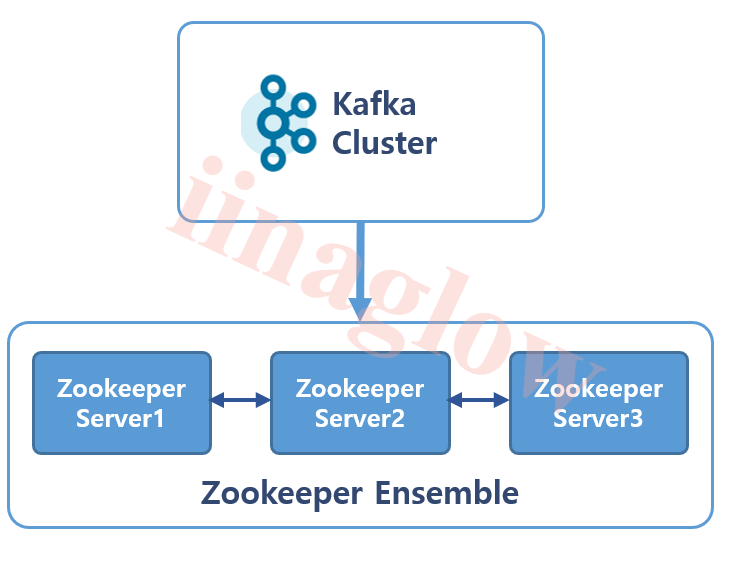
주키퍼는 서버 간의 정보를 중앙에서 효과적으로 관리하는 코디네이터 역할을 합니다. 주키퍼는 브로커의 상태 정보나 파티션 할당 정보와 같은 메타데이터를 관리하여 Kafka 시스템이 안정적으로 동작할 수 있도록 지원합니다.
Zookeeper
- Broker를 관리해주는 소프트웨입니다.
- 홀수의 서버로 작동하게 설계되었습니다. (최소 3, 권장 5)
- Broker들 간의 정보 공유 및 동기화를 수행합니다.
- “주키퍼의 종속성”을 없애는
KRaft 모드가 출시되었는데 Kafka 3.3에서 정식 릴리즈되어 Kafka 4.0부터는 Kraft 모드만 지원하는 것으로 계획되어 있어 향후 사용되지 않을 것으로 보여집니다.
4. 커넥트 & 커넥터 (Connect & Connector)
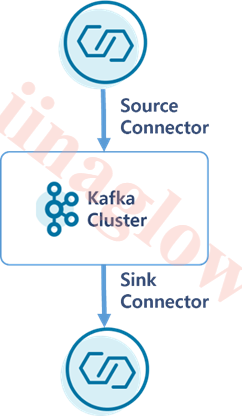
Connect는 외부시스템(DB 등) 간의 파이프라인 구성을 쉽게 해주는 프레임워크로 Connector를 동작시키는 프로세스 입니다.
Connector는 외부 시스템과 Kafka 간의 데이터를 효율적으로 전송할 수 있도록 도와주는 컴포넌트입니다. 커넥터는 크게 두 가지로 나뉩니다.
- Source Connector: 외부 시스템에서 Kafka로 데이터를 가져옵니다.
- Sink Connector: Kafka에서 외부 시스템으로 데이터를 보냅니다.
예를 들어, 특정 DB에서 데이터를 가져와 Kafka에 저장하고 싶다면 JDBC Source Connector를 이용할 수 있습니다. 반대로, Kafka 토픽의 데이터를 다른 DB로 전송하기 위해서는 JDBC Sink Connector를 사용합니다.
커넥터를 사용하면 개발자가 직접 프로듀서와 컨슈머를 개발하지 않아도 되므로, 개발 시간을 절약할 수 있고 외부 시스템 간의 데이터 흐름을 더 효율적으로 관리할 수 있습니다.
5. 컨슈머 그룹 (Consumer Group)
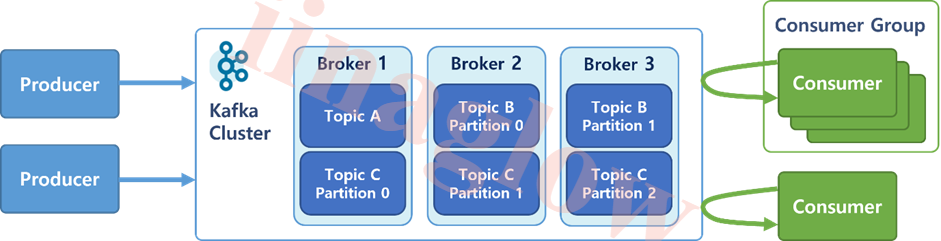
컨슈머 그룹은 여러 consumer들이 협력하여 하나의 토픽에서 데이터를 처리할 수 있도록 합니다. Consumer Group을 통해 메시지 처리의 병렬성과 확장성을 쉽게 관리할 수 있습니다.
Consumer Group
- Topic의 메시지를 사용하기 위해 협력하는 Consumer들의 집합입니다.
- 하나의 Consumer는 하나의 Consumer Group에 포함됩니다.
- Consumer Group내의 Consumer들은 협력하여 Topic의 메시지를 분산 병렬 처리합니다.
결론
Kafka는 다양한 컴포넌트들이 유기적으로 작동하여 대규모 실시간 데이터 스트리밍을 처리합니다.
프로듀서와 컨슈머를 통해 데이터를 주고받고, 토픽과 파티션을 통해 데이터를 분산 저장하며, 브로커와 주키퍼를 통해 시스템의 안정성을 유지합니다.
마지막으로, 커넥터를 통해 외부 시스템과의 데이터를 효율적으로 전송할 수 있습니다.
Kafka의 이러한 구성 요소들을 잘 이해하고 활용하면, 대규모 데이터 처리 시스템을 효과적으로 구축할 수 있습니다.
Comments powered by Disqus.