[Coherence] Coherence*Web Cache Server 동작 방식
Coherence*Web Cache Server 개념
코히어런스 캐시 서버 동작 방식에 대한 오라클 공식 문서를 참고하여 작성한다.
coherence 3.7.1.22 버전 기준으로 작성됨
Coherence Cache Server 동작 방식
Oracle Coherence의 캐시 서버는 세션 저장 방식을 Near Cache로 구성한다. Near Cache는 Local Cache와 Distributed Cache (Primary/Backup)를 결합한 방식이다.
Local Cache는 MRU(Most Recently Used), MFU(Most Frequently Used) 알고리즘을 사용하여 최근에 가장 많이 사용된 데이터를 로컬 캐시에 저장함
Distributed Cache는 데이터를 primary와 backup으로 나누어 분산 저장함
- primary, backup을 찾는 매커니즘은 문서에 자세히 나와있지 않지만, 한쪽 서버로만 몰리지 않게 분배하여 동작하며, primary와 backup 각각 서로 다른 서버에 우선적으로 분배됨
- 세션 복구 시, backup 데이터가 primary로 전환되며, primary를 가진 멤버는 다른 멤버들에게 backup count만큼 새로운 backup을 생성
- backup count의 기본값은 1
- 일부 멤버가 죽어도 시스템은 자동으로 데이터를 복구하여 세션 데이터를 찾아올 수 있게 설계됨
또한, WebLogic과 Coherence 간의 연결 방식은 primary와 backup의 개수만큼 연결이 형성된다.
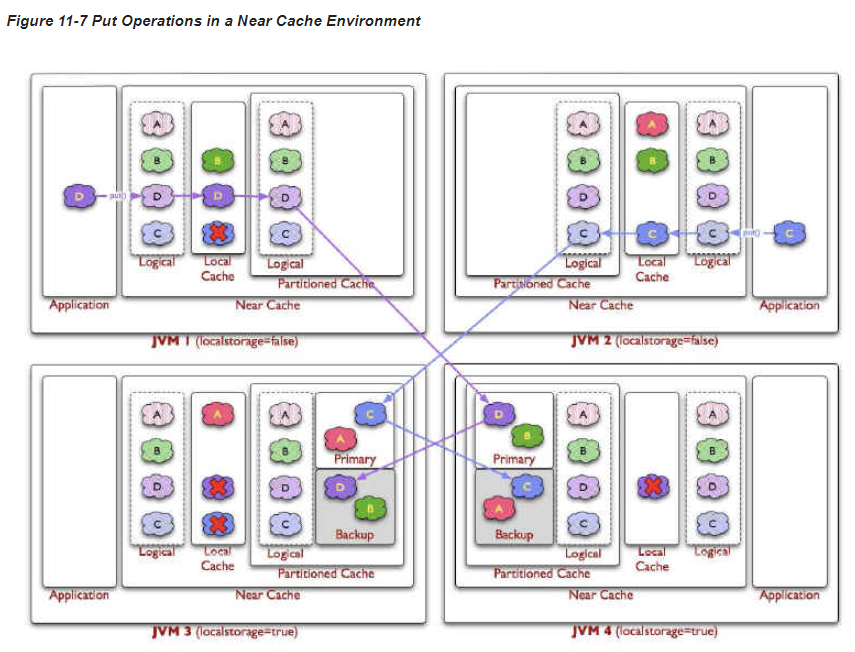
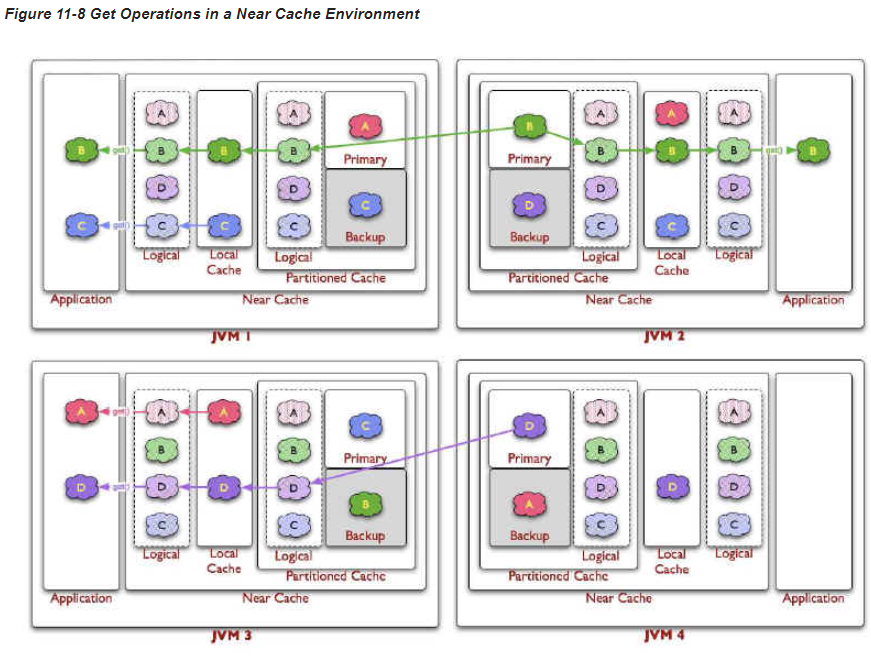
참고 1) WebLogic 인스턴스가 살아있고, Cache Server가 모두 Down 된 경우 미치는 영향
- 모든 WebLogic 인스턴스에서 localstorage=false 라면, Cache Server 전체 Down 시 500 Error 발생
- 재기동이 잦은 웹로직 인스턴스는 localstorage=false 권장
- Weblogic 인스턴스가 1개라도 localstorage=true 라면, Cache Server 역할도 하기 때문에 Cache Server 전체 Down되어도 500 Error 발생 X
- primary, backup이 존재하는 Cache Server를 동시에 내리면 session data가 유실되기에, rolling restart 방식으로 Cache Server Restart 필요
참고 2) 멤버 내의 Death Detection 인지 방법
Death Detection: 클러스터 내의 노드(서버)나 프로세스의 상태를 모니터링하고, 특정 노드가 실패하거나 응답하지 않을 때 이를 감지하는 메커니즘
- TCP-Ring 구성: 클러스터의 모든 멤버가 TCP-Ring을 통해 서로 연결
- 하트비트(heartbeat) 신호: 각 멤버는 1초 간격(기본값)으로 서로 하트비트 신호를 주고받아, 다른 멤버가 정상적으로 작동하고 있는지 확인
- 사망 감지: 하트비트 신호가 특정 시간 내에 도달하지 않으면, 해당 멤버가 죽었거나 응답하지 않는 것으로 간주
- 프로세스 및 하드웨어 감지: TCP-Ring을 통해 프로세스의 죽음을 감지하고, IpMonitor를 사용하여 하드웨어 실패도 감지
- 멤버 제거: 이상이 있는 멤버는 클러스터에서 자동으로 제거
References
This post is licensed under CC BY 4.0 by the author.
Comments powered by Disqus.